MacWhisper のモデルを日本語で比較する
MacWhisper は OpenAI の Whisper モデルを使って音声からの文字起こしを行う GUI アプリケーションですが、モデル選択画面の Quality グラフが日本語においては正確でない場合があります。そこで、品質が高く高速なモデル 3 つに絞って比較を行いました。
比較するモデル
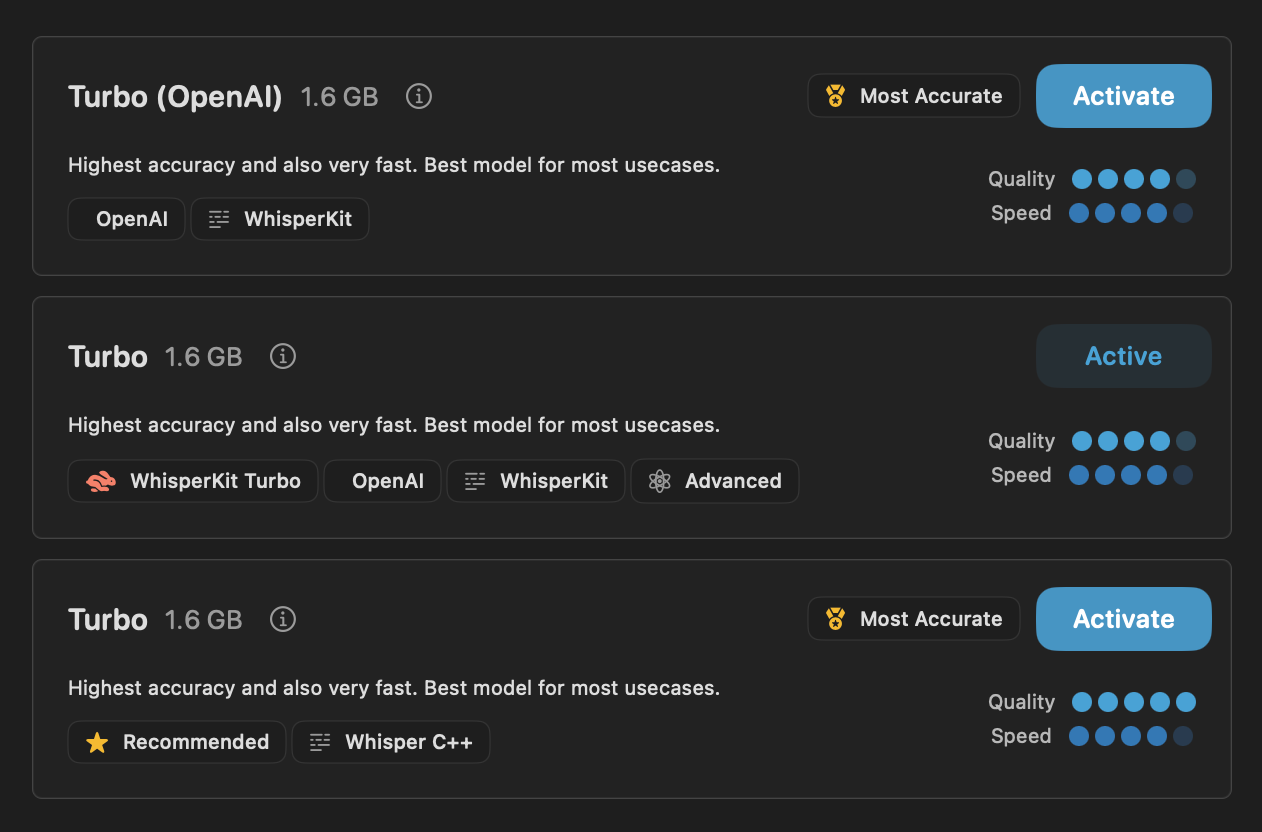
こちらの 3 モデルを比較します。
比較方法
1 時間程度の日本語音声を 1 度ずつ書き起こしました。厳密に速度を測る必要がないためこのようにしています。環境は次のとおりです。
- MacBook Air (M3, 24GB, 2TB)
- macOS Sequoia 15.1
- MacWhisper v11.1
比較結果
モデル選択画面とメインウインドウでモデル名が異なるので、両方の名前を併記しています。
| モデル | 実時間に対する書き起こし速度 | 品質 | 実装 |
|---|---|---|---|
| Turbo (OpenAI) / Large v3 Turbo | 12.8 倍速 | 誤認識が少ない。やや文を短く区切りる傾向がある。 | WhisperKit |
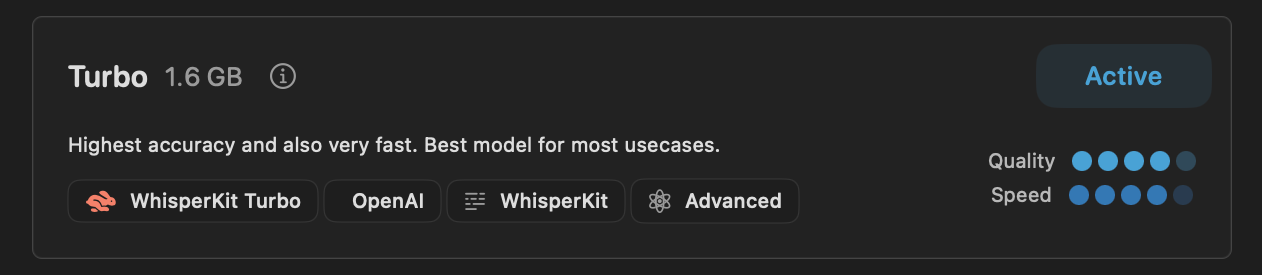
| Turbo / Openai Whisper-Large-V3-V20240930 Turbo | 18.2 倍速 | 最も誤認識が少ない。まとまった量の文を一区切りにする傾向があり読みやすい。 | WhisperKit |
| Turbo / Turbo | 5.5 倍速 | やや誤認識が多い。文を短く区切る傾向があるので、読みやすさも少し劣る。 | Whisper C++ |
結論としては、WhisperKit Turbo タグのついた Turbo モデル が速度・品質の両面で最高の性能を発揮しました。モデル選択画面では Most Accurate タグもついていなければ Quality グラフも最良ではありませんが、日本語での利用においては別の傾向が見られるようですね。
おまけ
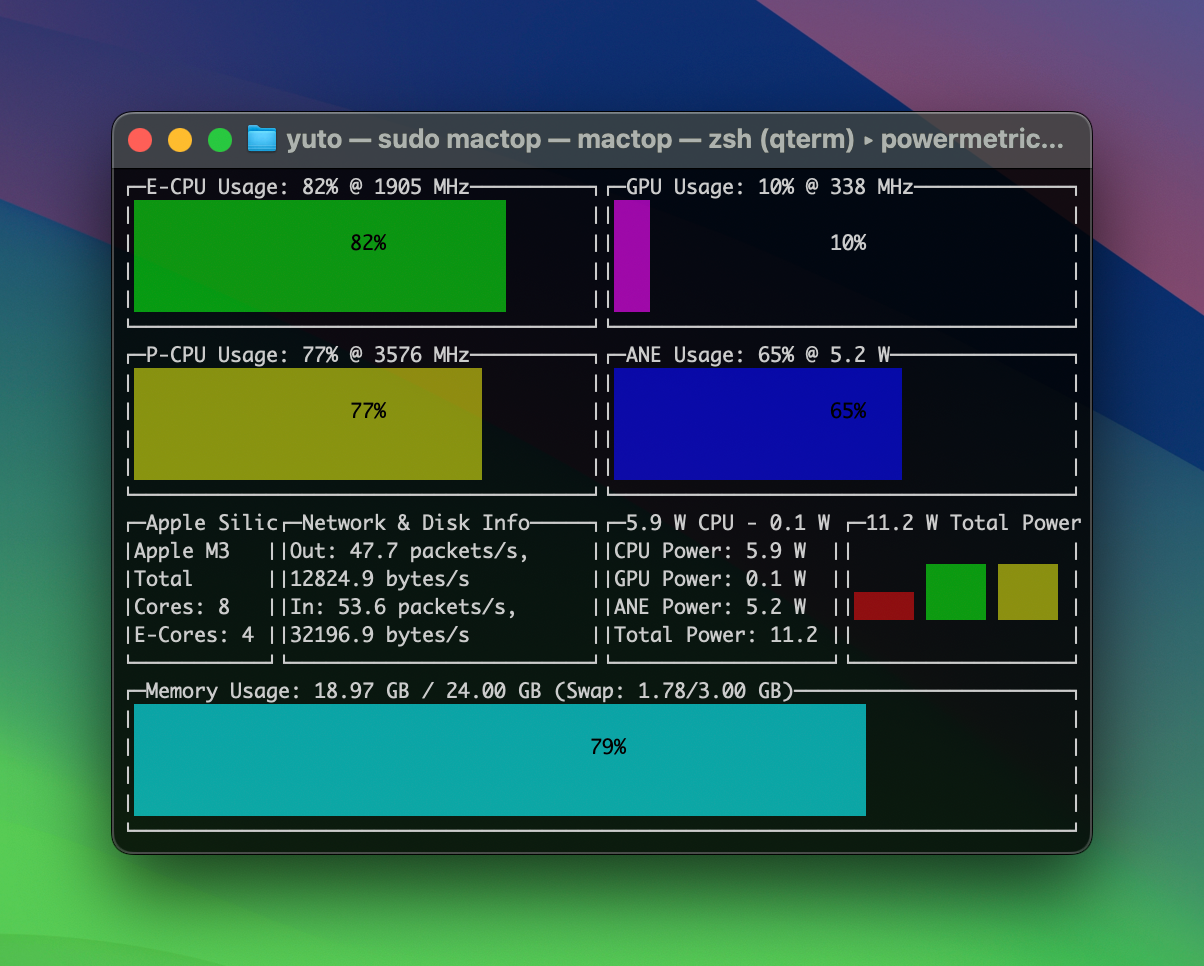
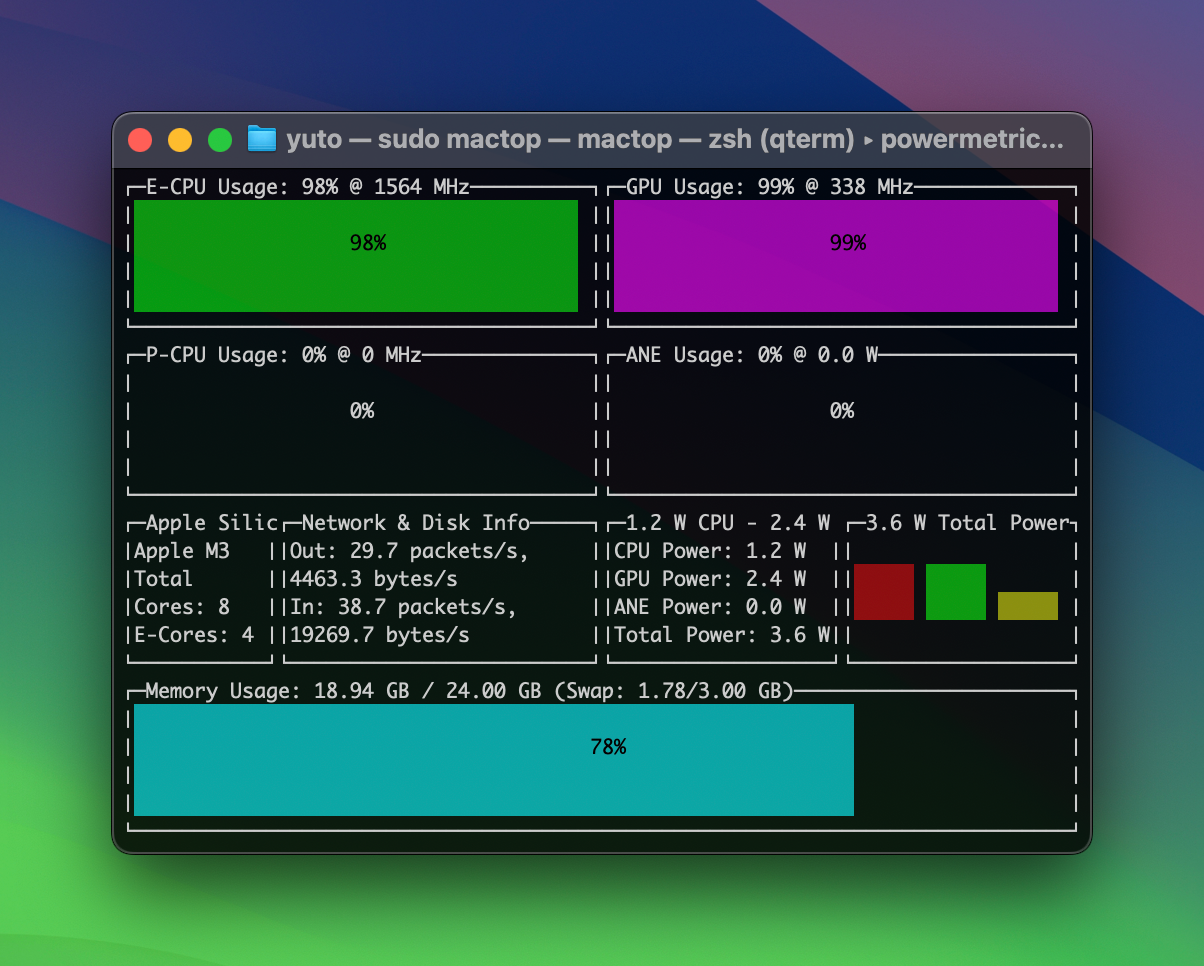
書き起こし中のプロセッサ使用率を確認しました。WhisperKit は CPU とニューラルエンジンで推論を行い、Whisper C++ は主に CPU と GPU で推論を行なっている様子が見られます。
また、現在の実装と M3 プロセッサにおいてはニューラルエンジンの推論速度が GPU による推論速度より速いと言えそうです。ただし、Ultra 系チップなど GPU が強力なプロセッサでは GPU 推論の方が速くなる可能性があります。面白いですね。
Turbo (OpenAI) / Large v3 Turbo - WhisperKit
Turbo / Openai Whisper-Large-V3-V20240930 Turbo - WhisperKit
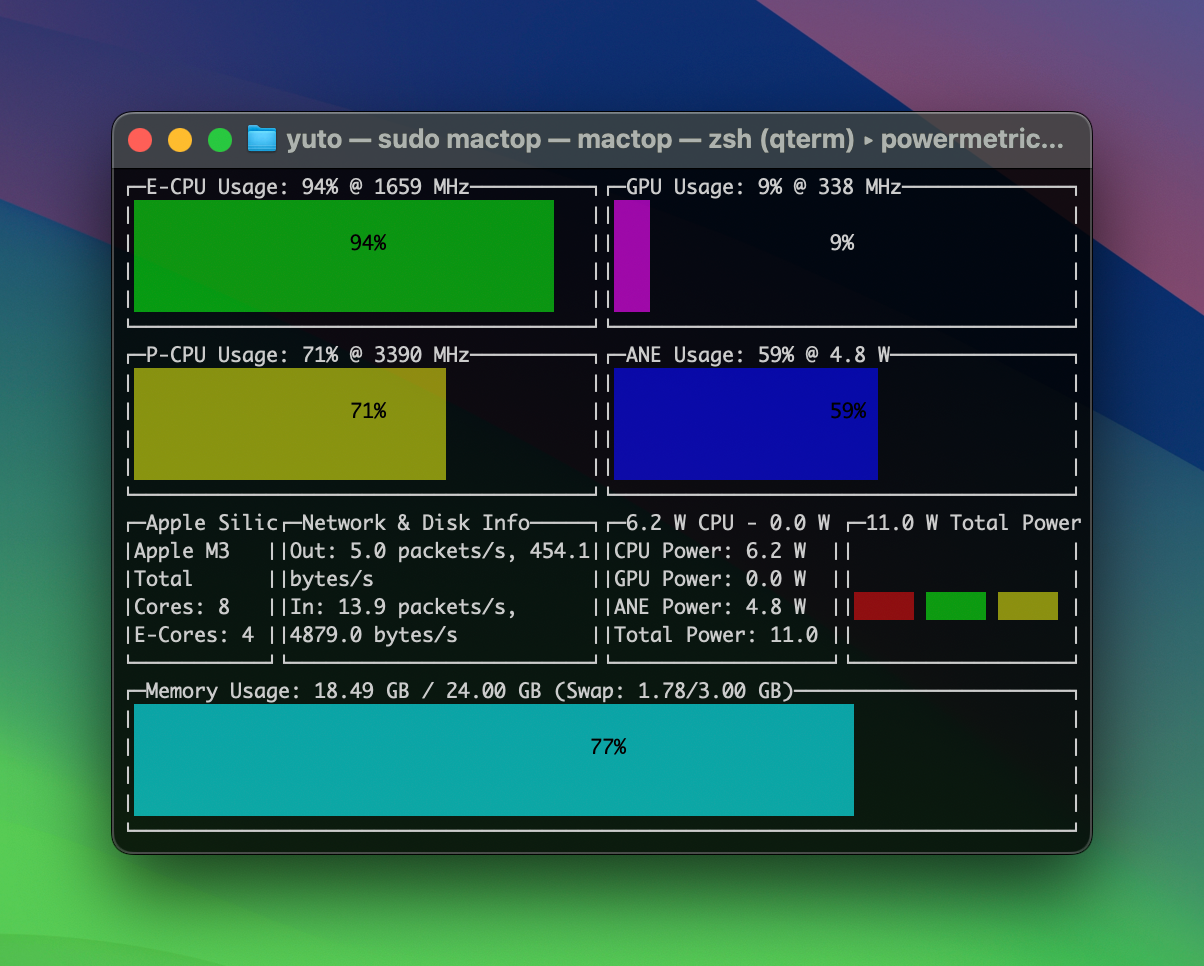
Turbo / Turbo - Whisper C++
2024年12月14日